1. Weight balancing
Train 데이터에서 각 loss 를 계산할 때 특정 클래스에 대해서는 더 큰 loss 를 계산해주는 방법.
- 클래스의 비율에 대해 가중치를 두는 방법이 있다. 예를 들어 두 개의 클래스 비율이 1:9라면 가중치를 9:1로 줌으로써 전체 클래스의 loss 에 동일하게 기여하도록 한다.

- Weight balancing 방법 중 Focal Loss 라는 방법도 있다. 어떤 딥러닝 분류 모델에서 A,B,C 라는 다중 클래스가 존재하고 A 클래스로 분류하기 쉽지만 상대적으로 B,C 클래스는 분류하기가 힘들다고 가정해보자. 100번의 Epoch 을 실시하고 10번의 Epoch 만에 99% 의 정확도를 얻었다고 했을 때 아무런 조치를 취하지 않으면 남은 90번의 Epoch 을 시행하는 동안 이미 A 클래스를 쉽게 분류할 수 있음에도 계속적으로 A 클래스 데이터에 대한 loss 값이 기여할 것이다. 그렇다면 A 클래스의 loss 가 기여하는 시간동안 B, C 클래스 데이터에 더 집중을 하면 전체적인 분류 정확도가 높아지지 않을까? 즉 1 번의 Epoch 을 실시하고 loss 에 의한 역전파(backpropagation) 방법을 통해 파라미터(weight 값)를 업데이트 하는데 이 순간에 loss 를 계산할 때 현재까지 클래스별 정확도를 고려하여 가중치를 준다면 더욱 더 모델의 분류 정확도가 높아지지 않을까 ?
한 번의 epoch 가 시행된 후 모든 클래스에 똑같은 가중치 값을 부여하는 것이 아닌 분류 성능이 높은 클래스에 대해서는 Down-weighting(가중치를 낮게 부여)을 한다. 위 그림에서 감마(Gamma) 값이 Down-weighting 값을 의미한다. 이러한 Down-weighting 방법은 분류가 힘든 클래스를 더욱 더 훈련시키는 효과가 있다.
2. Over and Under sampling
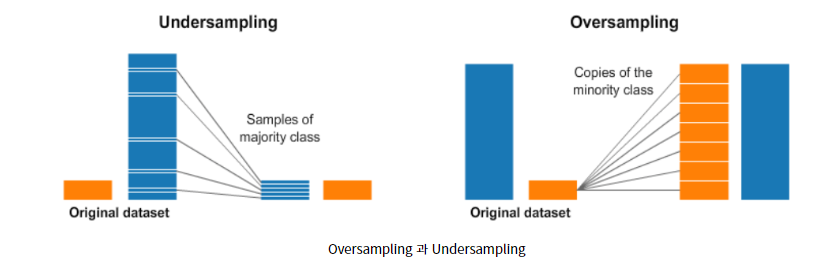
샘플링을 이용하는 것
Under sampling
Majority Class 의 일부만을 선택하고 Minority Class 는 최대한 많은 데이터를 사용하는 방법.
이 때 중요한 것은 양을 줄인 클래스의 값들을 대표할 수 있는 값들이 유지가 되는 것이 중요하다. 즉, 대표성이 있는 데이터들이 뽑혀야 한다는 의미이다.
Over sampling
Minority Class 의 복사본을 만들어, Majority Class 의 수만큼 데이터를 만들어주는 것이다. 똑같은 데이터를 그대로 복사하는 것이기 때문에 새로운 데이터는 기존 데이터와 같은 성질을 갖게된다.
# 참고 포스팅 글
https://techblog-history-younghunjo1.tistory.com/74
[ML] Class imbalance(클래스 불균형)이란?
이번 포스팅에서는 머신러닝 분류 문제에 있어서 '클래스 불균형' 에 대한 간단한 주제에 다룰 예정이다. 머신러닝 모델을 평가하는 하나의 지표로서 F1 score이란 것을 고려한다. F1 score은 Precision
techblog-history-younghunjo1.tistory.com
https://3months.tistory.com/414
딥러닝에서 클래스 불균형을 다루는 방법
딥러닝에서 클래스 불균형을 다루는 방법 현실 데이터에는 클래스 불균형 (class imbalance) 문제가 자주 있다. 어떤 데이터에서 각 클래스 (주로 범주형 반응 변수) 가 갖고 있는 데이터의 양에 차이
3months.tistory.com
'About AI (인공지능)' 카테고리의 다른 글
| 간단한 Binary Classification 구현 with linear layer (0) | 2023.03.23 |
|---|---|
| Cross Entropy Loss (pytorch 예제 +) (0) | 2023.03.23 |
| 벡터와 행렬 (1) | 2023.03.22 |

